What is tokenization ?
Machine learning models operate on numerical representations of input data. Language models, such as LLMs, work with text input. Tokenization is the process of converting the text into smaller chunks called tokens, which are then assigned numerical representations. The collection of unique tokens forms what we call a vocabulary. It is essentially a dictionary that maps each token to a unique integer. The size of the vocabulary is determined by the number of unique tokens in the corpus.
The vocabulary sizes of some popular LLMs are as follows:
- GPT-2: The vocabulary size is 50,257.
- GPT-3: The vocabulary size is approximately 175 billion.
- Llama 1: The vocabulary size is 32,000.
- Llama 2: The vocabulary size is also 32,000.
Larger vocabularies allow the model to understand and generate a wider range of words and phrases. However, they also require more computational resources (embedding size and softmax size increases) to train and use.
Broadly there are three types of tokenization we can do:
Character Tokenization: The text is broken down into characters, each character including whitespace and punctuation becomes a token. For example, ‘hello’ would be tokenized as [‘h’, ’e’, ’l’, ’l’, ‘o’].
Word Tokenization: In this method, the text is broken down into words. Each word becomes a token. For example, “it will rain today” would be tokenized as [“it”, “will”, “rain”, “today”].
Sub Word Tokenization: This method splits the text into smaller meaningful units, such as n-grams (sequence of n adjacent symbols). Some of the ways to do subword tokenization are:

- Byte Pair Encoding (BPE): Merges the frequent pair of tokens into single token.
- WordPiece:
- Sentence Piece
Selecting the appropriate tokenization method is crucial for NLP tasks. Incorrect tokenization can cause significant issues in language models (LLMs). The below are some of the reasons why LLMs fails due to tokenization.
- LLMs struggle with basic text processing tasks like string reversal.
- They falter in simple arithmetic.
- LLMs favor YAML over JSON.
- LLMs halts on encountering text such as ‘<|endoftext|>’.
- LLMs works poorly for languages other than english.
Visualizing Tokenization
Lets use the tiktokenizer.vercel.app to visualize how GPT-2 splits the text into tokens.
| Prompt | Tokenized (GPT-2) |
|---|---|
| Egg. A countryman has a goose that lays a golden egg every day, which he takes to market and sells. He becomes wealthy, but becomes impatient with the goose because it only lays one egg a day. | Token Count: 45  |
| 계란. 한 시골 사람에게 매일 황금알을 낳는 거위 한 마리가 있는데, 그는 그것을 시장에 내다 팔고 있습니다. 그는 부자가 되었지만 하루에 알을 한 개밖에 낳지 못하는 거위를 참을 수 없게 됩니다. | Token Count: 228  |
| Token Count: 63  |
Each color represents a different token. GPT-2 splits English text primarily based on words along with whitespace. Interestingly, “Egg” becomes two tokens: [‘E’, ‘gg’].
The same English text in the Korean language occupies more tokens. This can be due to multiple reasons such as:
- Dataset Bias: GPT might be trained on datasets with a larger proportion of English text compared to Korean. This can lead the tokenizer to be more efficient at handling English. As a result, it might need more tokens to represent the same meaning in Korean.
- Korean language characteristics: Korean inherently uses more characters per word than English. This simply means that Korean needs more building blocks to express the same idea, leading to a higher token count.
GPT-2 doesn’t perform well with programming languages like Python. It seems to struggle with Python indentation, often requiring multiple tokens to represent it. On the other hand, GPT-4 excels at identifying Python indentation, resulting in a lower token count for the same code snippet.
| Tokenized (GPT-4) | Tokenized (GPT-2) |
|---|---|
Token Count: 51  | Token Count: 63 |
Context Length
We have discussed the importance of token count and how a tokenizer that can tokenize input using a small number of tokens is desirable. The reason for a lower token count is due to the context length of Language Models (LLMs).
The context length of LLMs is the maximum number of tokens a model can process at once, meaning it is the number of tokens to which the model can attend. Context length plays a crucial role in LLMs and affects their ability to retain and attend to information from very old sequences. This directly impacts the quality of tasks such as summarization, long-term planning, and coherence in conversations.
Therefore, it is essential to have a tokenizer that can efficiently compress and tokenize the input text in the smallest number of tokens possible to take advantage of the available context length.
The context length of some popular LLMs are as follows:
- GPT-2: 1024 tokens
- GPT-3: 2048 tokens
- GPT-4: 32k tokens
- Llama 1: 2,048 tokens
- Llama 2: 4,096 tokens
Unicode
Unicode is a universal standard for character representation, assigning a unique code point (integer) to each character, regardless of platform, device, application, or language. It currently includes 149,813 characters across 161 scripts.
Previously, ASCII was the primary encoding standard, but it was limited by its 7-bit encoding, which only supports 128 characters, enough for English but not other scripts.
Unicode offers several encoding schemes:
UTF-8: Uses one-four bytes per code point. (variable length)
UTF-16: Uses one-two 16-bit units per code point. (variable length)
UTF-32: Uses 32-bit per code point. (fixed length)
UTF-8 is the most used due to its ASCII compatibility. The table below shows the UTF-8 conversion, where ‘x’ represents the bits of the code point. The graphs illustrate the space efficiency of UTF-8 compared to other encoding schemes.
 | Text: 오늘은 화창한 날이다 ☀️ (today is sunny day) 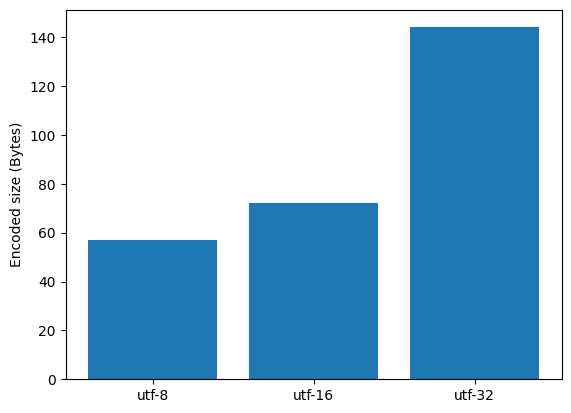 |
Below is the snippet to encode the text to utf-8 encoding in python.
# Convert the text into UTF-8 encoded string
text = "오늘은 화창한 날이다 ☀️ (today is sunny day)"
utf_8_encoded = text.encode("utf-8")
print(utf_8_encoded) # b'\xec\x98\xa4\xeb\x8a\x98\xec\x9d\x80 \xed\x99\x94\xec\xb0\xbd\xed\x95\x9c \xeb\x82\xa0\xec\x9d\xb4\xeb\x8b\xa4 \xe2\x98\x80\xef\xb8\x8f (today is sunny day)
# Calculate the size of the encoded string.
print("Size of encoded string: ", len(utf_8_encoded)) # 57 Bytes
Since, unicode already maps the each character to a unique integer, may be we can use it directly for tokenization ? - Using Unicode for tokenization isn’t ideal due to two main reasons:
- Unicode’s 149,813 unique characters would result in a large vocabulary, increasing the size of the embedding and softmax layers.
- As new characters are added to Unicode regularly, the network would need frequent re-training.
Byte-Pair Encoding
It’s evident from earlier sections that an ideal tokenizer encodes text into the fewest tokens and has a manageable vocabulary size.
Byte-Pair-Encoding (BPE) is a compression method that substitutes the most common byte pair with an unused byte. This byte is added to the vocabulary, creating a new one. This process continues until a set number of iterations are reached or all byte pairs in the input are unique.
Let’s look at an example for clarity.
# Initial text
aaabdaaabac (length: 11)
# Vocabulary
a,b,c,d
# Byte pairs and their counts
'aa': 4
'ab': 2
'bd': 1
'da': 1
'ba': 1
'ac': 1
Clearly, ‘aa’ is the most frequent pairs. Lets replace it with a new byte ‘Z’.
# New Text
ZabdZabac (length: 9)
# Vocabulary
a,b,c,d,Z=aa
# Byte pairs and their counts
'Za': 2
'ab': 2
'bd': 1
'dZ': 1
'ba': 1
'ac': 1
This time, ‘Za’ and ‘ab’ are the most frequent pairs. Lets take ‘ab’ and replace it with a new byte ‘X’.
# New Text
ZXdZXac (length: 7)
# Vocabulary
a,b,c,d,Z=aa,X=ab
# Byte pairs and their counts
'ZX': 2
'Xd': 1
'dZ': 1
'Xa': 1
'ac': 1
Repeat this process until no byte pair repeats more than once.
Building a Tokenizer
A tokenizer is independent of LLMs. It produces the output that LLMs process. Think of tokenization as a significant preprocessing step before any LLM-related tasks.

We’ll create a tokenizer using BPE to encode raw UTF text into tokens and decode them back to raw text.
Training Phase
The first step in building the tokenizer is to train it on a sufficiently large dataset containing a variety of languages and code/non-code data. This allows the tokenizer to learn the necessary statistics for the BPE algorithm. The training process involves two main steps: first, obtaining byte pairs and their frequencies, followed by replacing them with new bytes and adding these new bytes to the vocabulary. This process is then repeated for a specified number of iterations to compress the text. The choice of the number of iterations is a hyperparameter—a higher number leads to a larger vocabulary size and fewer tokens, but it’s essential to strike the right balance.

def get_tokens(utf_text):
"""
Accepts a UTF-8 encoded byte string and returns a
list of tokens, where each byte is mapped to an
integer between 0 and 255.
Args:
utf_text (bytes): A UTF-8 encoded byte string.
Returns:
list: A list of integers representing the tokens.
Example:
>>> utf_text = b"Hello, world!"
>>> get_tokens(utf_text)
[72, 101, 108, 108, 111, 44, 32, 119, 111, 114, 108, 100, 33]
"""
tokens = [ int(b) for b in utf_text ]
return tokens
def get_pairs(tokens_list):
"""
Generates byte pairs from a list of tokens and returns
a dictionary containing each unique byte pair along
with its frequency.
Args:
tokens_list (list): A list of tokens (integers).
Returns:
dict: A dictionary where keys are byte pairs (tuples)
and values are the frequency of each pair.
Example:
>>> tokens = [72, 101, 108, 108, 111, 44, 32, 119, 111, 114, 108, 100, 33]
>>> get_pairs(tokens)
{(72, 101): 1, (101, 108): 2, (108, 111): 1, (111, 44): 1, (44, 32): 1,
(32, 119): 1, (119, 111): 1, (111, 114): 1, (114, 108): 1, (108, 100): 1,
(100, 33): 1}
Note:
The input `tokens_list` should be a list of integer tokens.
The `stats` parameter (optional) allows updating an existing dictionary.
"""
token_list_len = len(tokens_list)
stats = {} if stats is None else stats
for idx in range(token_list_len-1):
p = (tokens_list[idx], tokens_list[idx+1])
if p not in stats.keys():
stats[p] = 1
else:
stats[p] += 1
return stats
def merge(tokens, pair_to_replace, replace_with):
"""
Replaces occurrences of a specific byte pair in a list of tokens
with a new byte value.
Args:
tokens (list): A list of integers representing tokens.
pair_to_replace (tuple): A tuple containing the byte pair to be replaced.
replace_with (int): The new byte value to replace the specified pair.
Returns:
list: A new list of tokens with the specified pair replaced.
Example:
>>> tokens = [72, 101, 108, 108, 111, 44, 32, 119, 111, 114, 108, 100, 33]
>>> pair_to_replace = (108, 111)
>>> replace_with = 999
>>> merge(tokens, pair_to_replace, replace_with)
[72, 101, 108, 999, 44, 32, 119, 111, 114, 108, 100, 33]
"""
new_tokens = []
idx = 0
while(idx < len(tokens)):
if (idx < len(tokens)-1) and (tokens[idx] == pair_to_replace[0]) and \
(tokens[idx+1] == pair_to_replace[1]):
new_tokens.append(replace_with)
idx += 2
else:
new_tokens.append(tokens[idx])
idx += 1
return new_tokens
class Tokenizer:
"""
A class that implements a simple Byte-Pair Encoding (BPE) based tokenizer.
Attributes:
merges (dict): A dictionary mapping (int, int) pairs to new integer indices.
vocab (dict): A dictionary mapping integer indices to bytes.
Methods:
__init__(): Initializes the Tokenizer object.
_build_vocab(): Builds the initial vocabulary.
train(text: str, vocabSize: int, verbose: bool = True): Trains the tokenizer on input text.
encode(text: str) -> List[int]: Encodes input text into a list of integer tokens.
decode(tokens: List[int]) -> str: Decodes a list of integer tokens into text.
"""
def __init__(self):
"""
Initializes the Tokenizer object.
"""
self.merges = {} # (int, int) -> int
self.vocab = self._build_vocab() # int -> bytes
def _build_vocab(self):
"""
Builds the initial vocabulary.
Returns:
dict: A dictionary mapping integer indices to bytes.
"""
vocab = {idx: bytes([idx]) for idx in range(0, 256) }
return vocab
def train(self, text: str, vocabSize: int, verbose: bool=True):
"""
Trains the tokenizer on input text.
Args:
text (str): Input text for training.
vocabSize (int): Desired vocabulary size (must be greater than 256).
verbose (bool, optional): Whether to print training progress. Defaults to True.
"""
assert vocabSize > 256
numMerges = vocabSize - 256
# Convert text to bytes
utf_text = text.encode("utf-8")
# list of tokens - get_tokens()
ids = get_tokens(utf_text)
merges = {} # (int, int) -> (int)
for i in range(numMerges):
# Get the pair and their freq
pairs_stat = get_pairs(ids)
# Find the most freq pair
max_freq_pair = max(pairs_stat, key=pairs_stat.get)
freq = pairs_stat[max_freq_pair]
# Get the new byte to replace with
new_idx = 256 + i
# Replace the most freq pair
ids = merge(ids, max_freq_pair, new_idx)
# Save the merge and update vocab
merges[max_freq_pair] = new_idx
self.vocab[new_idx] = self.vocab[max_freq_pair[0]] + self.vocab[max_freq_pair[1]]
if verbose:
print("Iter: %d, Num Merges: %d, Vocab Size: %d."%(i+1, len(merges), len(self.vocab)))
self.merges = merges
def encode(self, text):
"""
Encodes input text into a list of integer tokens.
Args:
text (str): Input text to encode.
Returns:
List[int]: List of integer tokens.
"""
raise NotImplementedError
def decode(self, tokens):
"""
Decodes a list of integer tokens into text.
Args:
tokens (List[int]): List of integer tokens.
Returns:
str: Decoded text.
"""
raise NotImplementedError
Encoding
After training the tokenizer, we can encode any text by first converting it into the UTF-8 format and then applying the Byte-Pair Encoding (BPE) merges. Let’s update our encode method.
def encode(self, text):
"""
Encodes input text into a list of integer tokens.
Args:
text (str): Input text to encode.
Returns:
List[int]: List of integer tokens.
"""
# Convert text to bytes
utf_text = text.encode("utf-8")
# list of tokens - get_tokens()
ids = get_tokens(utf_text)
# Encode only if there is anything to merge.
if len(ids) >= 2 and len(self.merges) > 0:
# Get all initial byte pairs
pairs = get_pairs(ids)
# Iterate over all the merged pairs and replace it.
for p in self.merges.keys():
if p in pairs():
# Call merge function to replace the pair with the merged byte
new_ids = merge(ids, p, self.mergs[p])
ids = new_ids
# Re-calculate pairs
pairs = get_pairs(ids)
return ids
Decoding
The decoding process involves iterating over the encoded tokens and concatenating the corresponding bytes from the vocabulary. Let’s update our decode method.
Note: It is important to handle utf-8 decoding errors. The LLMs may spit out invalid utf-8 code points. When handling UTF-8 decoding errors, set the error mode to “replace” to avoid crashes due to invalid characters. This allows continued processing even if some parts are corrupted.
def decode(self, tokens):
"""
Decodes a list of integer tokens into text.
Args:
tokens (List[int]): List of integer tokens.
Returns:
str: Decoded text.
"""
text_bytes = b"".join([self.vocab[idx] for idx in tokens])
return text_bytes.decode("utf-8", errors="replace")
Regex-Based Rules for BPE in GPT-2
The GPT-2 researchers noticed that Byte-Pair Encoding (BPE) merges could result in multiple versions of common words, such as ‘dog,’ ‘dog!,’ and ‘dog?.’ BPE was merging based on punctuation, which was suboptimal because it assigned different vocabulary slots to the same word.
To address this issue, they introduced a rule for splitting input text. These rules were specified using a regex pattern. The regex pattern for GPT-2 is as follows.
import regex as re
# Taken from GPT-2 encoder.py - https://github.com/openai/gpt-2/blob/9b63575ef42771a015060c964af2c3da4cf7c8ab/src/encoder.py#L53C9-L53C113
pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")
print(re.findall(pat, "hello've world123 how are you!!!?"))
# ['hello', ''ve', ' world', '123', ' how', ' are', ' you', '!!!?']
This pattern consists of several alternatives and splits the text if any of them matches.
- Contractions: The initial seven patterns detect contractions and split tokens accordingly.
- Letters/Characters with Optional Space: The pattern
\p{L}+represents any sequence of letters or characters, which may include optional spaces at the start. - Numeric Characters with Optional Space: The pattern
\p{N}+matches any sequence of numeric characters (digits), with optional spaces at the beginning. - Non-Letters, Non-Numbers (Punctuation and Special Characters): The pattern
[^\s\p{L}\p{N}]identifies any character that is not a space, letter, or number. It specifically targets punctuation marks and other special characters. - Whitespace Excluding the Last Space: The expression
\s+(?!\S)|\s+captures any whitespace (spaces, tabs) except for the last space in a sequence.
After applying the input text to the regex pattern, it is split into multiple text tokens. Each of these tokens is then encoded in UTF-8 format and merged using Byte-Pair Encoding (BPE). To support the regex based split, we would need to update our Tokenizer class.
def __init__(self):
"""
Initializes the Tokenizer object.
"""
self.merges = {} # (int, int) -> int
self.vocab = self._build_vocab() # int -> bytes
# Defines a regex pattern to split the input text
self.regex_pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")
def train(self, text: str, vocabSize: int, verbose: bool=True):
"""
Trains the tokenizer on input text.
Args:
text (str): Input text for training.
vocabSize (int): Desired vocabulary size (must be greater than 256).
verbose (bool, optional): Whether to print training progress. Defaults to True.
"""
assert vocabSize > 256
numMerges = vocabSize - 256
# Convert text to bytes
utf_text = text.encode("utf-8")
# list of tokens - get_tokens()
ids = get_tokens(utf_text)
merges = {} # (int, int) -> (int)
for i in range(numMerges):
# Get the pair and their freq
pairs_stat = get_pairs(ids)
# Find the most freq pair
max_freq_pair = max(pairs_stat, key=pairs_stat.get)
freq = pairs_stat[max_freq_pair]
# Get the new byte to replace with
new_idx = 256 + i
# Replace the most freq pair
ids = merge(ids, max_freq_pair, new_idx)
# Save the merge and update vocab
merges[max_freq_pair] = new_idx
self.vocab[new_idx] = self.vocab[max_freq_pair[0]] + self.vocab[max_freq_pair[1]]
if verbose:
print("Iter: %d, Num Merges: %d, Vocab Size: %d."%(i+1, len(merges), len(self.vocab)))
self.merges = merges
Once the input text is split, each splited runs BPE through seperately and come up with its compressed form. These BPE merged individual tokens are then concatenated together to form the input. This is done to avoid unwanted pairing/merging of the tokens.
The GPT-4 introduced a better regex pattern.